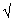 25 = 5.
25 = 5.
A sample is a set of observations drawn from a larger population. The sample is the numbers in hand. The population is the larger set from which the sample was taken. A sample is usually drawn to make a statement about the larger population from which it was taken. Sample and population are two different things.
Descriptive Statistics
After constructing graphical displays of a batch of numbers, the next thing to do is summarize the data numerically. Statistics are summaries derived from the data. The two important statistics that describe a single response are measures of location (typical value; the word location is a reference to the data's location on the number line) and spread (variability). The number of observations (the sample size, n) is important, too, but it is generally considered a "given". It is not counted as one of the summary statistics even though it fits the definition ("a function solely of the data") perfectly.
Mean and Standard Deviation
There are many reasonable single number summaries that describe where a set of values is located. Any statistic that describes a typical value will do. Statisticians refer to these measures, as a group, as averages.
The most commonly reported average is the mean--the sum of the observations divided by the sample size. The mean of the values 5, 6, 9, 13, 17 is (5+6+9+13+17)/5 or 50/5 = 10.
The mean is invariably what people intend when they say average. Mean is a more precise term than average because the mean can only be the sum divided by the sample size. There are other quantities that are sometimes called averages. These include the median (or middle value), the mode (most commonly occurring value), and even the midrange (mean of minumum and maximum values). Statisticians prefer means because they understand them better, that is, they understand the relation between sample and population means better than the relation between the sample and population value of other averages.
The most commonly reported measure of variability or spread is the standard deviation (SD). The SD is also called the "root-mean-square deviation", which describes the way it is calculated. The operations root, mean, and square are applied in reverse order to the deviations--the individual differences between the observations and the mean.
To see how the SD works, consider the values 5,6,9,13,17, whose mean as
we've already seen is 10. The deviations are {(5-10), (6-10), (9-10),
(13-10), (17-10)} or -5, -4, -1, 3, 7. (It is not an accident that the
deviations sum to 0, but I digress.) The squared deviations are 25, 16,
1, 9, 49 and the standard deviation is the square root of
(25+16+1+9+49)/(5-1), that is, the square root of (100/4) or
25 = 5.
Why do we use something that might seem so complicated? Why not the range (difference between the highest and lowest observations) or the mean of the absolute values of the deviations? Without going into details, the SD has some attractive mathematical properties that make it the measure of choice. It's easy for statisticians to develop statistical techniques around it. So we use it. In any case, the SD satisfies the most important requirement of a measure of variability--the more spread out the data, the larger the SD. And the best part is, we have computers to calculate the SD for us. We don't have to compute it. We just have to know how to use it...properly!
Some Mathematical Notation
Back in olden times, mathematics papers contained straightforward notation like
a+b+c+d+...
It was awkward having all of those symbols, especially if you wanted to be adding up heights, weights, incomes, and so on. So, someone suggested using subscripts and writing sums in the form
The plus signs could be eliminated by writing the expression as
![]()
Now all that was left was to replace the S by its Greek equivalent, sigma, and here we are in modern times!
![]()
Because we almost always sum from 1 to 'n', the limits of summation are often left off unless the sum is not from 1 to 'n'.
Now that we have this nice notation, let's use it to come up with expressions for the sample mean, which we'll write as the letter 'x' with a bar over it, and the standard deviation, s. The mean is easy. It's the sum of the observations (which we've already done) divided by the sample size
![]()
![]() .
.
The standard deviation isn't much more difficult. Recall "root-mean-square". Begin with the deviations
![]()
![]()
then square them
![]()
then take their "mean"
![]()
then take a square root
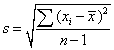 .
.
All done.![]()
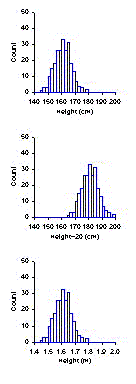 If you're the mathematical type,
you can prove these statements for yourself by using the formulas just
developed for the mean and standard deviation. If you're the visual type,
you should be able to see why these results are so by looking at the
pictures to the left.
If you're the mathematical type,
you can prove these statements for yourself by using the formulas just
developed for the mean and standard deviation. If you're the visual type,
you should be able to see why these results are so by looking at the
pictures to the left.
Mental Pictures
The mean and SD are a particularly appropriate summary for data whose histogram approximates a normal distribution (the bell-shaped curve). If you say that a set of data has a mean of 220, the typical listener will picture a bell-shaped curve centered with its peak at 220.
What information does the SD convey? When data are approximately normally distributed,
Percentiles
When the histogram of the data does not look approximately normal, the mean and SD can be misleading because of the mental picture they paint. Give people a mean and standard deviation and they think of a bell-shaped curve with observations equally likely to be a certain distance above the mean as below. But, there's no guarantee that the data aren't really skewed or that outliers aren't distorting the mean and SD, which would invalidate the rule of thumb, from the last section, describing the proportion of observations within so many SDs of the mean.
One way to describe such data in a way that does not give a misleading impression of where they lie is to report some percentiles. The p-th percentile is the value that p-% of the data lie are less than or equal to. If p-% of the data lie below the p-th percentile, it follows that (100-p)-% of the data lie above it. For example, if the 85-% percentile of household income is $60,000, then 85% of households have incomes of $60,000 or less and the top 15% of households have incomes of $60,000 or more.
The most famous of all percentiles--the 50-th percentile--has a special name: the median. Think of the median as the value that splits the data in half--half of the data are above the median; half of the data are below the median*. Two other percentiles with special names are the quartiles: the lower quartile (the 25-th percentile) and the upper quartile (the 75-th percentile).
The median and the quartiles divide the data into quarters:
Sometimes the minimum and maximum are presented along with the median and the quartiles to provide a five number summary of the data. Unlike a mean and SD, this five number summary can be used to identify skewed data. When there are many observations (hundreds or thousands), some investigators report the 5-th and 95-th percentiles (or the 10th and 90- th or the 2.5-th and the 97.5-th percentiles) instead of the minimum and maximum to establish so-called normal ranges.
You'll sometimes see the recommendation that the Inter-Quartile Range (the difference between the upper and lower quartiles) be reported as a measure of spread. It's certainly a measure of spread--it measures the spread of the middle half of the data. But as a pair, the median and IQR have the same deficiency as the mean and the SD. There's no way a two number summary can describe the skewness of the data. When one sees a median and an IQR, one suspects they are being reported because the data are skewed, but one has no sense of how skewed! It would be much better to report the median and the quartiles.
In practice, you'll almost always see means and SDs. If your goal is to give a simple numerical summary of the distribution of your data, look at graphical summaries of your data to get a sense of whether the mean and SD might produce the wrong mental picture. If they might, consider reporting percentiles instead.
Mean versus Median
The mean is the sum of the data divided by the sample size. If a histogram could be placed on a weightless bar and the bar on a fulcrum, the histogram would balance perfectly when the fulcrum is directly under the mean. The median is the value in the middle of the histogram. If the histogram is symmetric, the mean and the median are the same. If the histogram is not symmetric, the mean and median can be quite different. Take a data set whose histogram is symmetric. Balance it on the fulcrum. Now take the largest observation and start moving it to the right. The fulcrum must move to the right with the mean, too, if the histogram is to stay balanced. You can make the mean as large as you want by moving this one observation farther and farther to the right, but all this time the median stays the same!
A point of statistical trivia: If a histogram with a single peak is skewed to the right, the order of the three averages lie along the measurement scale in reverse alphabetical order--mode, median, mean.
Geometric Mean
When data do not follow a normal distribution, reports sometimes contain a statement such as, "Because the data were not normally distributed, {some transformation} was applied to the data before formal analyses were performed. Tables and graphs are presented in the original scale."
When data are skewed to the right, it often happens that the histogram looks normal, or at least symmetric, after the data are logged. The transformation would be applied prior to formal analysis and this would be reported in the Statistical Methods section of the manuscript. In summary tables, it is common for researchers to report geometric means. The geometric mean is the antilog of the mean of the logged data--that is, the data are logged, the mean of the logs is calculated, and the anti-log of the mean is obtained. The presence of geometric means indicates the analysis was done in the log scale, but the results were transformed back to the original scale for the convenience of the reader.
If the histogram of the log-transformed data is approximately symmetric, the geometric mean of the original data is approximately equal to the median of the original data.
The accuracy of the approximation will depend on the extent to which the distribution in the log scale is symmetric.
Is there a geometric SD? Yes. It's the antilog of the SD of the log transformed values. The interpretation is similar to the SD. If GBAR is the geometric mean and GSD is the geometric standard deviation, 95% of the data lie in the range from GBAR/(GSD2) to GBAR*(GSD2), that is, instead of adding and subtracting 2 SDs we multiply and divided by the square of the SD.
These differences follow from properties of the logarithm, namely,
log(ab) = log(a) + log(b) and
log(a/b) = log(a) - log(b)
that is, the log of a product is the sum of the logs, while the log of a ratio is the difference of the logs.
Since the data are approximately normally distributed in the log scale, it follows that 95% of the data lie in the range mean-2SD to mean+2SD. But this is
log(GBAR) + log(GSD) + log(GSD) = log(GBAR*GSD2) and
log(GBAR) - log(GSD) - log(GSD) = log(GBAR/GSD2)
------------
*This definition isn't rigorous for two reasons. First, the median may not be unique. If there is an even number of observations, then any number between the two middle values qualifies as a median. Standard practice is to report the mean of the two middle values. Second, if there is an odd number of observations or if the two middle values are tied, no value has half of the data greater than it and half less. A rigorous definition of the median is that it is a value such that at least half of the data are less than or equal to it and half of the data are greater than or equal to it. Consider the data set 0,0,0,0,1,7. The median is 0 since 4/6 of the data are less than or equal to 0, while all of the data are greater than or equal to 0. Similar remarks apply to all other percentiles. However, so we don't get bogged down in details, let's think of the p-th percentile as the value that has "p-% of the data below it; (100-p)-% of the data above it".
**If the number of observations is even, it is more correct to say that the log of a median in the original scale is a median in the log scale. That's because when the number of observations is even, any value between the two middle values satisfies the definition of a median. Standard practice is to report the mean of the two middle values, but that's just a convention.
Consider a data set with two observations--10 and 100, with a median of 55. Their common logarithms are 1 and 2, with a median of 1.5. Now, log(55)=1.74 which is not 1.5. Nevertheless, 1.74 is a median in the log scale since it lies between the two middle values.